
多伦多大学和致力于促进AI的独立非营利组织Vector Institute的科学家提出了BabyAI ++,该平台用于研究描述性文本是否有助于AI跨动态概括。环境。它和几个基准模型都将很快在GitHub上提供。
机器学习中最强大的技术之一-强化学习,即通过奖励激励软件代理实现目标,也是最有缺陷的技术之一。它的样本效率低下,这意味着需要大量的计算周期才能完成,并且没有其他数据来覆盖变化,因此它很难适应与训练环境不同的环境。
从理论上讲,可以将通过结构化语言对任务的先验知识与强化学习相结合,以减轻其缺点,而BabyAI ++旨在对该理论进行测试。为此,该平台建立在现有的强化学习框架BabyAI的基础上,以生成各种动态的,基于彩色图块的环境以及详细描述其布局的文本。
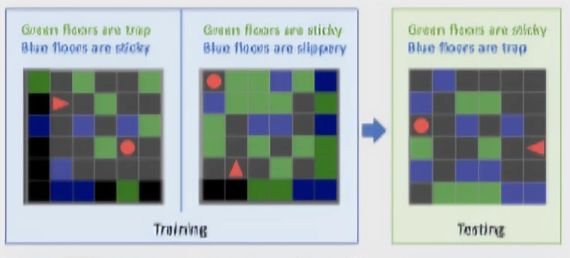
BabyAI ++的级别由可以拾取和放置的对象组成。可以解锁和打开的门;以及代理商必须承担的各种任务。像环境本身一样,任务是随机生成的,并通过“婴儿语言”(一种使用一部分英语词汇的组合语言)传达给代理。
上述文本揭示了正在使用的瓷砖类型以及与每个瓷砖匹配的颜色。由于颜色和图块类型之间的配对是随机的,因此代理必须了解其描述才能正确导航地图。
在BabyAI ++中,每个级别都分为两种配置:培训和测试。在训练配置中,代理会暴露于该级别中的所有图块和颜色类型,但会阻止颜色类型对的某些组合。在测试配置中,将启用所有颜色类型对,从而迫使代理使用语言基础将图块的类型与颜色相关联。
本文介绍了使用基准模型进行的几项实验,其中一项(注意力融合)使用所谓的注意力机制将相关文本嵌入(数学表示)分配给场景嵌入特征图(映射嵌入的功能)上的位置到要素空间或AI处理的变量所在的尺寸)。对于最困难的级别,此注意力融合模型的测试成功率(经过5个步骤或动作后达到60%的测试成功率)比最具挑战性的次优模型高16.2%,并且使用更少的帧完成了该级别的图片数量(约65相比75)。
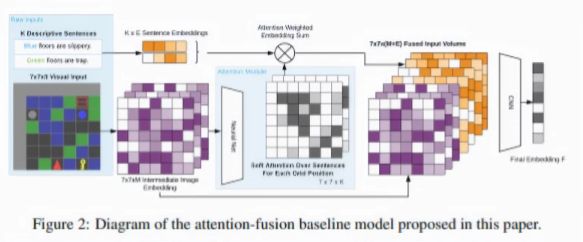
合著者断言,这表明描述性文本对于代理人通过学习语言基础来概括具有可变动态的环境很有用。他们在论文中写道:“我们相信,所提议的BabyAI ++平台及其公共代码和基准实现将进一步刺激这一领域的研究开发。”
