
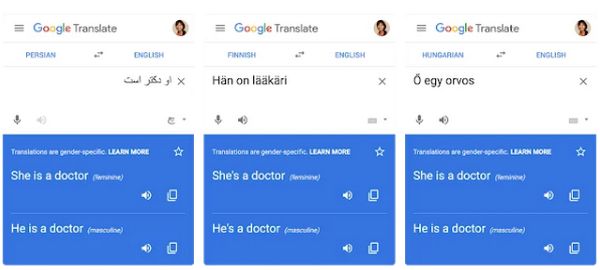
Google今天宣布在Google翻译中发布英语到西班牙语以及芬兰语,匈牙利语和波斯语到英语的性别专用翻译,这些翻译利用新的范例来通过重写或后期编辑初始翻译来解决性别偏见。这家科技巨头声称,这种方法比支持Google Translate的针对性别的土耳其语到英语翻译的早期技术更具可扩展性,主要是因为它不依赖于数据密集型的性别中立检测器。
Google Research高级软件工程师梅尔文·约翰逊(Melvin Johnson)写道:“自最初发布以来,我们已经取得了重大进展,不仅提高了按性别划分的翻译质量,还将其扩展到另外4种语言对。” “我们致力于进一步解决Google Translate中的性别偏见,并计划将这项工作扩展到文档级翻译。”
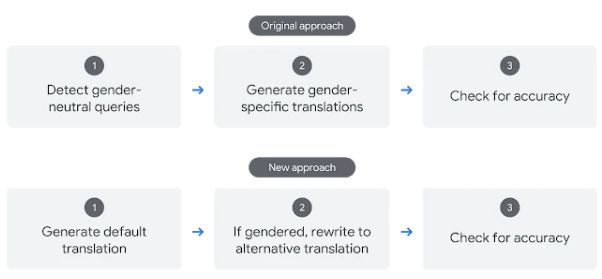
正如约翰逊所解释的那样,用于土耳其语到英语性别特定翻译的旧分类器费力地适应新语言,但是却无法使用神经机器翻译(NMT)系统独立生成男性和女性翻译。而且,它无法显示多达40%的合格查询的针对性别的翻译,因为除性别相关现象外,这两种翻译通常不完全相同。
相比之下,新的基于重写的方法首先生成翻译,然后对其进行审阅,以识别性别中立的源短语产生特定性别翻译的实例。如果真是如此,那么句子级的重写者会选择另一种性别翻译,然后对第一和重写译文进行审核,以确保唯一的区别是性别。
根据Google的说法,构建重写器涉及生成数百万个由成对短语组成的训练示例,每个短语都包含男性和女性翻译。由于数据不易获得,因此Google Translate团队不得不从大型单语数据集开始,通过将性别代词从男性转换为女性(或相反)来提出候选者重写。对于这种重写语料库,工程师采用了针对数百万个英语句子进行训练的内部语言模型,以选择最佳候选人,从而将训练数据从男性输入转化为女性输出,反之亦然。
在从两个方向合并了训练数据之后,该团队使用它来训练一个基于Transformer的单层序列到序列模型。然后,他们在训练数据中引入了标点符号和大小写变体,以提高模型的健壮性,从而使最终模型可以在99%的时间内可靠地生成所要求的男性或女性重写。
约翰逊说,对Google开发的一种称为“偏倚减少”的指标进行了评估,该指标用于衡量新翻译系统与现有系统之间偏向的相对减少(其中“偏见”是指在翻译中未指定性别的性别选择),新方法可将匈牙利语,芬兰语和波斯语的英语翻译偏差减少90%以上。现有土耳其语到英语系统的偏差减少从60%提高到95%,并且该系统触发了针对性别的翻译,平均精度为97%-即,当它决定显示针对性别的翻译时,这是正确的97%的时间。
数月后,谷歌取消了使用Cloud Vision API将图像中的人标记为“男人”或“女人”的功能,从而改进了Google翻译系统的部署。另外,在2018年1月,谷歌阻止了Smart Compose(一种Gmail功能),该功能会在提示用户键入句子时自动为他们建议基于性别的代词。
Google为减轻AI系统的偏见而做出的更大努力的一部分是采用不分性别的语言翻译和计算机视觉方法。这家位于山景城(Mountain View)的公司使用其AI道德团队开发的测试来发现偏见,并从其预测技术中禁止任何粗鄙的言论,种族诽谤,提及商业竞争对手和悲剧事件。
