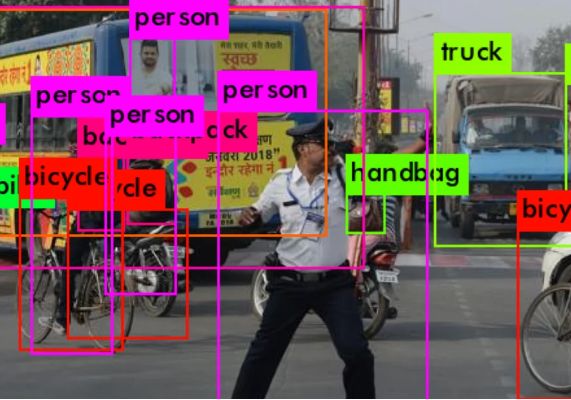
微软和华中大学的研究人员团队本周开放了AI对象检测器的源代码- 公平多对象跟踪(FairMOT),他们声称在公共数据集上以每秒30帧的速度优于最新模型。如果产品化了,它可以使从老年护理到安全领域的各个行业受益,并且可能被用来跟踪像COVID-19这样的疾病的传播。
正如该团队所解释的那样,大多数现有方法都采用多种模型来跟踪对象:(1)定位感兴趣对象的检测模型,以及(2)提取用于重新识别短暂遮挡对象的特征的关联模型。相比之下,FairMOT采用无锚方法在高分辨率特征图上估计对象中心,这使重新识别特征可以更好地与中心对齐。并行分支估计用于预测对象身份的特征,而“主干”模块将这些特征融合在一起以处理不同比例的对象。
研究人员在从六个公共语料库收集的训练数据集上对FairMOT进行了测试,以供人类检测和搜索:ETH,CityPerson,CalTech,MOT17,CUHK-SYSU和PRW。(在两张Nvidia RTX 2080图形卡上进行了30小时的培训。)在删除了重复的剪辑后,他们针对2DMOT15,MOT16和MOT17等基准测试了经过训练的模型。所有这些都来自MOT挑战赛,该挑战赛是用于验证数据集附带的人员追踪算法的框架,提供多个指标的评估工具以及用于监视和体育分析等任务的测试。

与仅有的两个联合执行对象检测和身份特征嵌入的著作TrackRCNN和JDE相比,该团队报告FairMOT在MOT16数据集上均以“接近视频速率”的推理速度胜过两者。

“近年来,在目标检测和重新识别方面取得了显着进展,这是多目标跟踪的核心组成部分。但是,很少有人关注在单个网络中完成两项任务以提高推理速度。研究人员在描述FairMOT 的论文中总结道:“沿着这条路进行的最初尝试最终导致了降级的结果,这主要是因为重新识别分支的学习不正确。” “我们发现在对象检测和身份嵌入中使用锚点是导致结果下降的主要原因。特别是,对应于对象的不同部分的多个附近的锚点可能负责估计相同的身份,这会导致网络训练不明确。”
除了FairMOT的源代码,研究团队还提供了几种可以在实时或录制的视频上运行的预训练模型。
