
在今年早些时候悄悄发布的技术论文中,IBM详细介绍了所谓的IBM神经计算机,这是一种定制设计,可重新配置的并行处理系统,旨在研究和开发新兴的AI算法和计算神经科学。本周,该公司发布了预印本,描述了在神经计算机上演示的第一个应用程序:一种深度的“神经进化”系统,该系统将Atari 2600的硬件实现,图像预处理和AI算法结合在优化的流水线中。合著者报告的结果与最先进的技术相比具有竞争力,但也许更重要的是,他们声称该系统实现了创纪录的每秒120万图像帧的训练时间。
神经计算机代表了AI计算军备竞赛中弓箭的一击。根据OpenAI最近发布的一项分析,从2012年到2018年,最大规模的AI培训运行中使用的计算量增长了300,000倍,是3.5个月的两倍,远远超过了摩尔定律的步伐。与此相伴,诸如英特尔即将在能源部的阿贡国家实验室的Aurora和AMD 在橡树岭国家实验室的Frontier等超级计算机的计算性能超过了exaflop(每秒五百万浮点计算)。
电子游戏是AI和机器学习研究的完善平台。他们之所以获得成功,不仅是因为它们的可用性和大规模运行它们的低成本,而且因为在诸如强化学习之类的某些领域中,人工智能通过与环境互动以获取奖励来学习最佳行为,因此游戏得分是直接的奖励。游戏中开发的AI算法已显示出可适应更实际的用途,例如蛋白质折叠预测。而且,如果证明来自IBM神经计算机的结果是可重复的,则该系统可以用于加速这些AI算法的开发。
神经计算机
IBM的神经计算机包括432个节点(16个模块化卡中的27个节点),这些节点基于Xilinx的现场可编程门阵列(FPGA),后者是IBM的长期战略合作者。(FPGA是设计用于制造后配置的集成电路。)每个节点都包含一个Xilinx Zynq片上系统(一个双核ARM A9处理器与一个FPGA在同一芯片上配对)以及1GB专用RAM。节点以3D网格拓扑结构排列,并与称为穿硅通孔的电气连接垂直互连,这些通孔完全穿过硅晶圆或芯片。

在联网方面,FPGA提供对卡之间物理通信链接的访问,以建立多个不同的通信通道。理论上,单个卡可以支持每秒432GB的传输速度,但是可以调整和逐步优化神经计算机的网络接口,以使其最适合给定的应用程序。
“在每个节点上FPGA资源的可用性允许特定于应用程序的处理器卸载,这一功能在我们所知的任何规模的并行计算机上均不可用,” 详细描述了神经计算机架构的论文的共同作者写道。“ [大多数]性能关键步骤已在FPGA上卸载和优化,而ARM [处理器]…提供了辅助支持。”
用AI玩Atari游戏
研究人员在神经计算机中每个卡的27个节点中使用了26个,对总共416个节点进行了实验。他们的Atari游戏应用程序的两个实例(分别从给定的Atari 2600游戏中提取帧,执行图像预处理,通过机器学习模型运行图像并在游戏中执行操作)分别在416个FPGA上运行,从而扩大规模到832个并行运行的实例。
为了获得最高的性能,该团队避免仿真Atari 2600,而是选择使用FPGA在更高的频率下实现控制台的功能。他们利用了开源MiSTer项目的框架,该项目旨在使用现代硬件重新创建控制台和街机,并将Atari 2600的处理器时钟从3.58 MHz提高到150 MHz。每秒产生约2514帧,而最初的每秒60帧。
在图像预处理步骤中,IBM的应用程序将帧从彩色转换为灰度,消除了闪烁,将图像缩放为较小的分辨率,然后将帧堆叠为四组。然后将这些信息传递到推理游戏环境的AI模型和一个子模块,该子模块通过识别AI模型所预测的最大奖励来选择下一帧的动作。
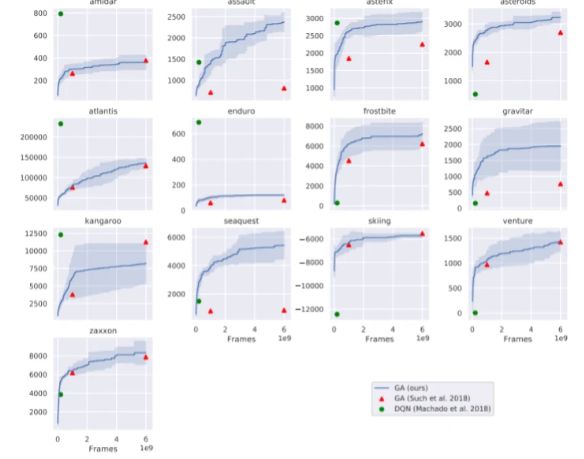
另一算法(遗传算法)在通过PCIe连接连接到神经计算机的外部计算机上运行。它评估了每个实例的性能,并确定了性能最高的实例,并选择该实例作为下一代实例的“父级”。
在5个实验的过程中,IBM研究人员在神经计算机上运行了59个Atari 2600游戏。结果表明,与其他强化学习技术相比,该方法的数据效率不高-总共需要60亿个游戏框架,但在蒙特祖玛的《复仇》和《陷阱》等具有挑战性的探索性游戏中失败了。但是,经过6分钟的训练(2亿个训练帧),而Deep-Q网络经过10 天的训练,它在59款游戏中有30场的表现超过了流行的基准-Deep Q-网络,这是DeepMind率先提出的架构。它拥有60亿个训练帧,在36场比赛中超过了Deep Q网络,而训练时间却减少了2个数量级(2小时30分钟)。
