在预印本学术论文发表在四月上旬,麻省理工学院的研究人员描述了量化的检疫措施对COVID-19,该新型冠状病毒的传播影响的模型。与迄今提出的大多数模型不同,该模型不依赖于有关SARS或MERS等先前暴发研究的数据。取而代之的是,它使用了经过训练的AI算法,该算法经过训练,可以使用SEIR模型捕获隔离区中的受感染个体数量,将人们分为“易感”,“暴露”,“感染”和“恢复”等类别。
与以前的工作相比,此方法有可能实现更高的准确性,这可能有助于更好地为政府,卫生系统和非营利组织提供有关社会隔离的治疗和政策决策的信息。例如,该模型发现,在韩国等受到政府立即干预的地方,该病毒的传播速度更快达到了平稳状态。
“我们的模型表明,隔离限制可以成功地将有效繁殖数从大于1减少到小于1。[模型]正在学习我们所谓的“隔离控制强度函数”。候选人Raj Dandekar作为期末课程的一部分。“这对应于我们可以使曲线变平坦并开始减少感染的点。”
在每个地区(分别于1月24日,2月27日和2月22日分别对武汉,意大利和韩国进行记录)记录了第500个案例之后,使用从武汉(中国),意大利,韩国和美国收集的数据对MIT模型进行了训练,直到4月1日为止。经过500次迭代,它学会了预测感染传播的模式,在隔离措施与病毒有效繁殖数量减少之间建立了相关性。
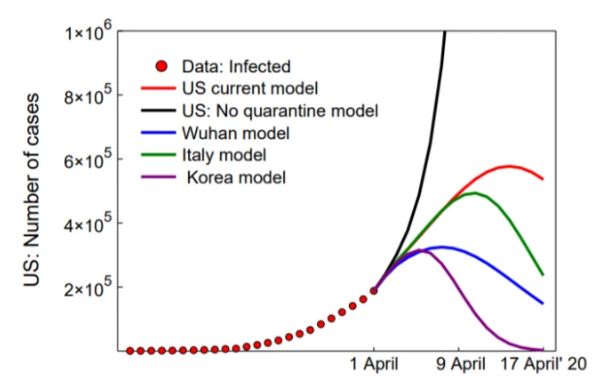
随着特定国家/地区病例数的减少,预测模型将从指数形式(表明病毒呈指数传播)过渡到线性形式(表明感染正在稳定)。意大利从4月初开始进入这种线性体制,该模型预计,美国将在4月15日至20日之间进行类似的过渡,这与健康指标与评估研究所的其他预测类似。
该模型还预测,在感染率开始停滞之前,美国的感染人数将达到60万。
“这是一个非常关键的时刻。如果我们放松检疫措施,可能会导致灾难。” Barbastathis说。“如果美国过早采取同样的放松检疫措施的政策,我们预计后果将是灾难性的。”
MIT模型与Microsoft,印度理工学院和TCS Research(塔塔咨询服务的R&D部门)的研究人员于今年早些时候发布的模型相吻合,该模型可以根据疾病参数(如传染性,妊娠期,症状持续时间,死亡可能性,人口密度和运动倾向。在持续了52周(364天)的模拟过程中,进行了75次模拟,结果表明,锁定5%至10%社区的政府的COVID-19感染高峰期较低。
另外,一个国际研究小组使用百度提供的人类流动性数据来阐明COVID-19传播在中国城市中的作用。他们发现,在实施控制和围堵措施之后,COVID-19病例的地理分布与流动性之间的相关性下降,并且大多数地区的增长率都为负,这表明这些措施减轻了COVID-19的传播。
这就是说,要记住,即使是最好的AI模式是很重要的-就像那些由疾病警报,Metabiota,开发蓝点,这是第一个准确地识别COVID-19的传播当中-只是学会从历史数据中的模式。如布鲁金斯学会所指出在最近的一份报告中,虽然某些流行病学模型采用了AI,但流行病学家在很大程度上采用了包含主题专业知识的统计模型。该报告的作者写道:“仅凭准确性就不足以评估预测的质量。” “如果管理不当,AI算法将花费大量精力寻找与尝试结果相关的数据模式。但是,这些模式可能完全是荒谬的,仅在开发期间有效。
